

 夜黎
夜黎本文章內容基於萊斯大學 OpenStax 的 Anatomy and Physiology 2e,由夜黎重新編輯。(根據本書前言中的創用 CC BY 4.0 聲明)
原文傳送門:<3> The Cellular Level of Organization — 3.4 Protein Synthesis
索引傳送門:《解剖學和生理學2e》索引頁面
學習本章後,你將能夠:
- 解釋 DNA 中存儲的遺傳密碼如何決定將要形成的蛋白質
- 描述轉錄過程
- 描述翻譯過程
- 討論核醣體的功能
前言
前面提到DNA為細胞結構和生理學提供了“藍圖〔blueprint〕”。 這指的是DNA包含了細胞構建一種非常重要的分子所需的信息:蛋白質。 細胞的大多數結構成分至少一部分由蛋白質組成,並且細胞執行的幾乎所有功能都是在蛋白質的幫助下完成的。 最重要的一類蛋白質是酶,它有助於加速細胞內發生的必要生化反應。 其中一些關鍵的生化反應包括用較小的成分構建較大的分子(例如在DNA 複製或微管合成期間發生)以及將較大的分子分解為較小的成分(例如從營養分子中收穫化學能時)。 無論細胞過程是什麼,幾乎肯定都涉及蛋白質。 正如細胞的基因組描述了其完整的 DNA 一樣,細胞的蛋白質組〔proteome〕也是其完整的蛋白質。 蛋白質的合成從基因開始。 基因〔gene〕是 DNA 的功能性節段,提供構建蛋白質所需的遺傳信息。 每個特定的基因都提供構建特定蛋白質所需的代碼。 基因表達〔Gene expression〕將基因中編碼的信息轉化為最終的基因產物,通過確定產生哪些蛋白質,最終決定細胞的結構和功能。
基因的解釋按以下方式進行。 回想一下,蛋白質是許多氨基酸構件的聚合物〔polymers〕或鏈〔chains〕。 基因中的鹼基序列(即其 A、T、C、G 核苷酸序列)可翻譯為氨基酸序列〔amino acid sequence〕。 三聯體〔triplet〕是連續的三個 DNA 鹼基的一部分,編碼特定的氨基酸。 與三字母代碼 d-o-g 表示狗的圖像的方式類似,三字母 DNA 鹼基代碼表示特定氨基酸的使用。 例如,DNA 三聯體 CAC(胞嘧啶、腺嘌呤和胞嘧啶)指定氨基酸纈氨酸〔amino acid valine〕。 因此,由獨特序列中的多個三聯體組成的基因提供了構建完整蛋白質的代碼,該蛋白質具有正確序列中的多個氨基酸(圖3.25)。 細胞將 DNA 代碼轉化為蛋白質產物的機制是一個兩步過程,以 RNA 分子作為中間體〔intermediate〕。
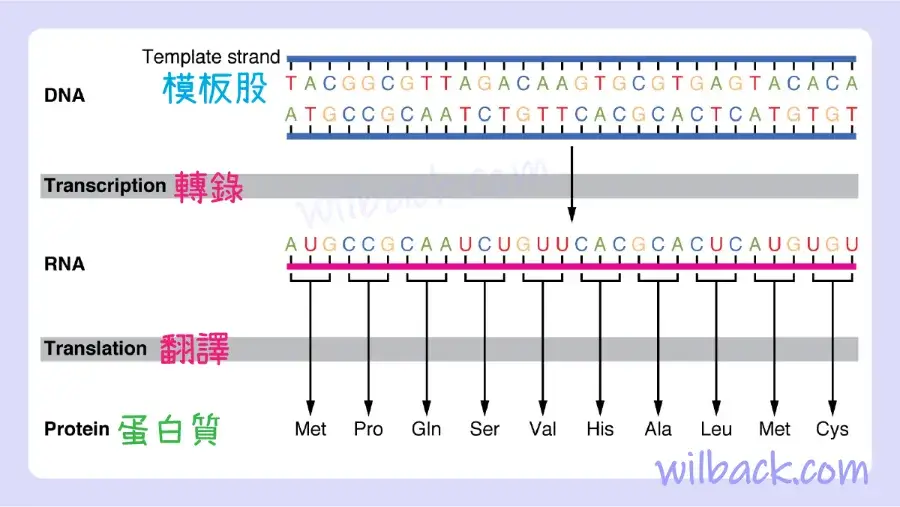
DNA 包含構建細胞蛋白質所需的所有遺傳信息。 基因的核苷酸序列最終被翻譯成該基因相應蛋白質的氨基酸序列。
從 DNA 到 RNA:轉錄
DNA 位於細胞核內,蛋白質合成發生在細胞質中,因此必須有某種中間信使離開細胞核並管理蛋白質合成。 這種中間信使是信使RNA (mRNA)〔messenger RNA〕,它是一種單股核酸〔single-stranded nucleic acid〕,將單個基因的遺傳密碼的副本攜帶出細胞核並進入細胞質,並在細胞質中用於生產蛋白質。
RNA 有多種不同類型,每種在細胞中具有不同的功能。 RNA 的結構與 DNA 相似,但有一些小的例外。 一方面,與 DNA 不同,大多數類型的 RNA(包括 mRNA)都是單股的,不包含互補股〔complementary strand〕。 其次,與DNA相比,RNA中的核糖含有一個額外的氧原子。 最後,RNA 含有尿嘧啶鹼基〔base uracil〕,而不是胸腺嘧啶鹼基〔base thymine〕。 這意味著在蛋白質合成過程中,腺嘌呤〔adenine〕總是與尿嘧啶〔uracil〕配對。
基因表達始於稱為轉錄〔transcription〕的過程,即「與目的基因互補的 mRNA 股的合成」。 這個過程稱為轉錄,因為 mRNA 就像基因 DNA 代碼的轉錄本或副本。 轉錄開始的方式有點像DNA複製,DNA的一個區域解旋,兩條股分開,然而,只有一小部分DNA會被分開。 DNA 分子這部分基因內的三聯體被用作轉錄 RNA 互補股的模板(圖 3.26)。 密碼子〔codon〕是 mRNA 的三鹼基序列〔three-base sequence〕,之所以這麼稱呼是因為它們直接編碼氨基酸。 與 DNA 複製一樣,轉錄也分為三個階段:起始〔initiation〕、伸長〔elongation〕和終止〔termination〕。
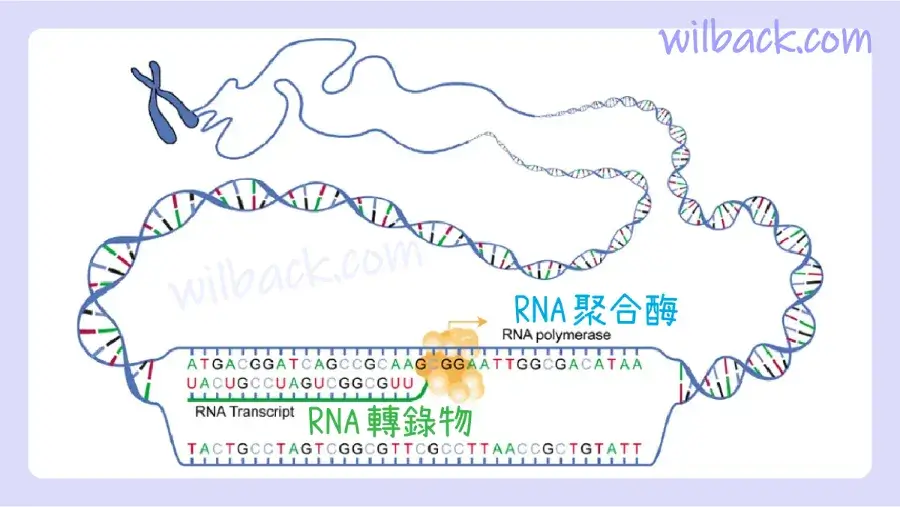
在從 DNA 製造蛋白質的兩個階段中的第一個階段,DNA 分子上的基因被轉錄成互補的 mRNA 分子。
基因開頭的一個區域(稱為啟動子〔promoter〕)——一段特定的核苷酸序列——觸發轉錄〔transcription〕的開始。
當 RNA 聚合酶解開 DNA 片段時,轉錄開始。 其中一股稱為編碼股〔coding strand〕,成為具有待編碼基因的模板。 然後,聚合酶將正確的核酸(A、C、G 或 U)與其 DNA 編碼股上的互補鹼基進行對齊。 RNA 聚合酶是一種向不斷增長的 RNA 股添加新核苷酸的酶。 這個過程構建了一條 mRNA 股。
在基因末端,一段稱為終止子序列〔terminator sequence〕的核苷酸序列會導致新的 RNA 自行折疊。 這種折疊導致 RNA 與基因和 RNA 聚合酶分離,從而結束轉錄。
在 mRNA 分子離開細胞核並進行蛋白質合成之前,它會以多種方式進行修飾。 因此,此階段通常被稱為前 mRNA〔pre-mRNA〕。 例如,你的 DNA 以及互補的 mRNA 包含稱為非編碼區〔non-coding regions〕的長區域,這些區域不編碼氨基酸。 它們的功能仍然是個謎,但稱為剪接〔splicing〕的過程從前 mRNA 轉錄物中去除了這些非編碼區域(圖 3.27)。 剪接體〔spliceosome〕——一種由各種蛋白質和其他分子組成的結構——附著在 mRNA 上並“剪接〔splices〕”或切除非編碼區。 轉錄物〔transcript〕中被移除的片段稱為內含子〔intron〕。 剩餘的外顯子〔exons〕粘貼在一起。 外顯子是剪接後保留的 RNA 片段。 有趣的是,一些從 mRNA 中去除的內含子並不總是非編碼的。 當mRNA的不同編碼區被剪接時,最終會產生不同的蛋白質變異,其結構和功能也有所不同。 這個過程產生了更多種類的可能蛋白質和蛋白質功能。 當 mRNA 轉錄物準備好時,它就會離開細胞核並進入細胞質。
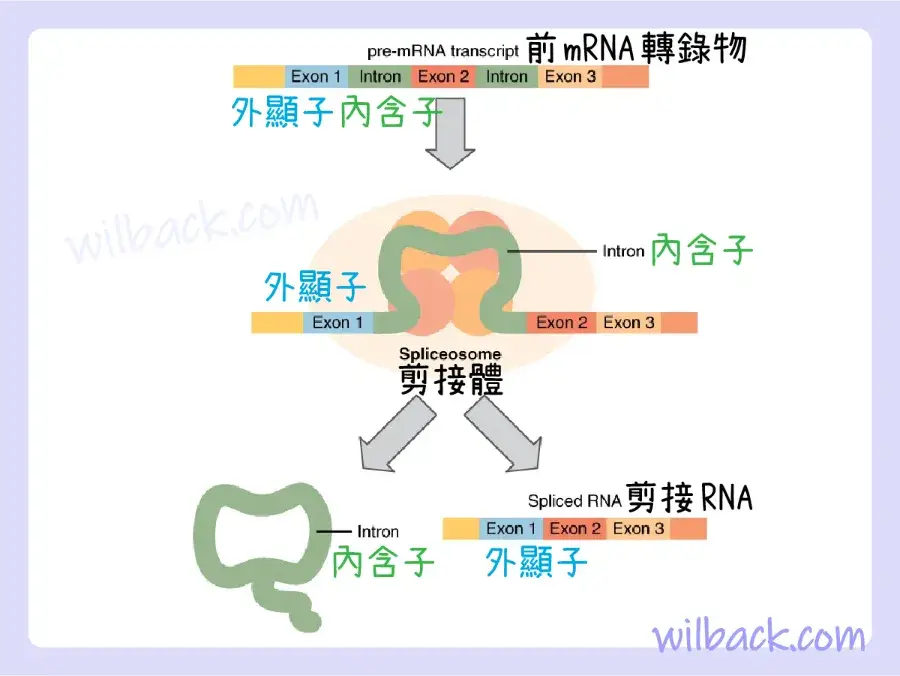
在細胞核中,一種稱為剪接體〔spliceosome〕的結構會切除前 mRNA 轉錄物中的內含子〔introns〕(非編碼區域)並重新連接外顯子〔exons〕。
從 RNA 到蛋白質:翻譯
就像將一本書從一種語言翻譯成另一種語言一樣,mRNA 股上的密碼子〔codons〕必須翻譯成蛋白質的氨基酸字母表。 翻譯〔translation〕是合成稱為多胜肽〔polypeptide〕的氨基酸鏈的過程。 翻譯需要兩個主要輔助工具:第一是“翻譯者〔translator〕”,即進行翻譯的分子;第二是 mRNA 股在其上被翻譯成新蛋白質的受質〔substrate〕,就像翻譯者的“辦公桌〔desk〕”。 其他類型的 RNA 可以滿足這兩個要求。 發生翻譯的受質〔substrate〕是核醣體〔ribosome〕。
請記住,許多細胞的核醣體被發現與粗糙內質網相關,並合成運往高基氏體的蛋白質。 核醣體 RNA (rRNA) 〔ribosomal RNA〕是一種 RNA,與蛋白質一起構成核醣體的結構。 核醣體作為兩個不同的成分存在於細胞質中,一個小亞基和一個大亞基。 當 mRNA 分子準備好翻譯時,兩個亞基會聚集在一起並附著在 mRNA 上。 核醣體為翻譯提供了受質,將 mRNA 分子與必須破譯其代碼的分子“翻譯者”聚集在一起並對齊。
蛋白質合成的另一個主要要求是物理“讀取”mRNA 密碼子的翻譯分子。 轉移RNA (tRNA) 〔transfer RNA〕是一種RNA,它將適當的相應氨基酸運送到核醣體,並將每個新氨基酸連接到最後一個氨基酸,逐一構建多胜肽鏈〔polypeptide chain〕。 因此,tRNA 將特定氨基酸從細胞質轉移到生長的多胜肽上。 tRNA 分子必須能夠識別 mRNA 上的密碼子並將其與正確的氨基酸進行匹配。 tRNA 已針對此功能進行了修飾。 其結構的一端是特定氨基酸的結合位點〔binding site〕。 另一端是與指定其特定氨基酸的密碼子相匹配的鹼基序列〔base sequence〕。 tRNA 分子上的三個鹼基序列稱為反密碼子〔anticodon〕。 例如,負責穿梭氨基酸甘氨酸的 tRNA 一端含有甘氨酸〔glycine〕結合位點。 在另一端,它包含一個與甘氨酸密碼子互補的反密碼子(GGA 是甘氨酸的密碼子,因此 tRNA 反密碼子將讀取為 CCU)。 配備有其特定的貨物和匹配的反密碼子,tRNA 分子可以讀取其識別的 mRNA 密碼子並將相應的氨基酸帶到不斷增長的鏈中(圖 3.28)。
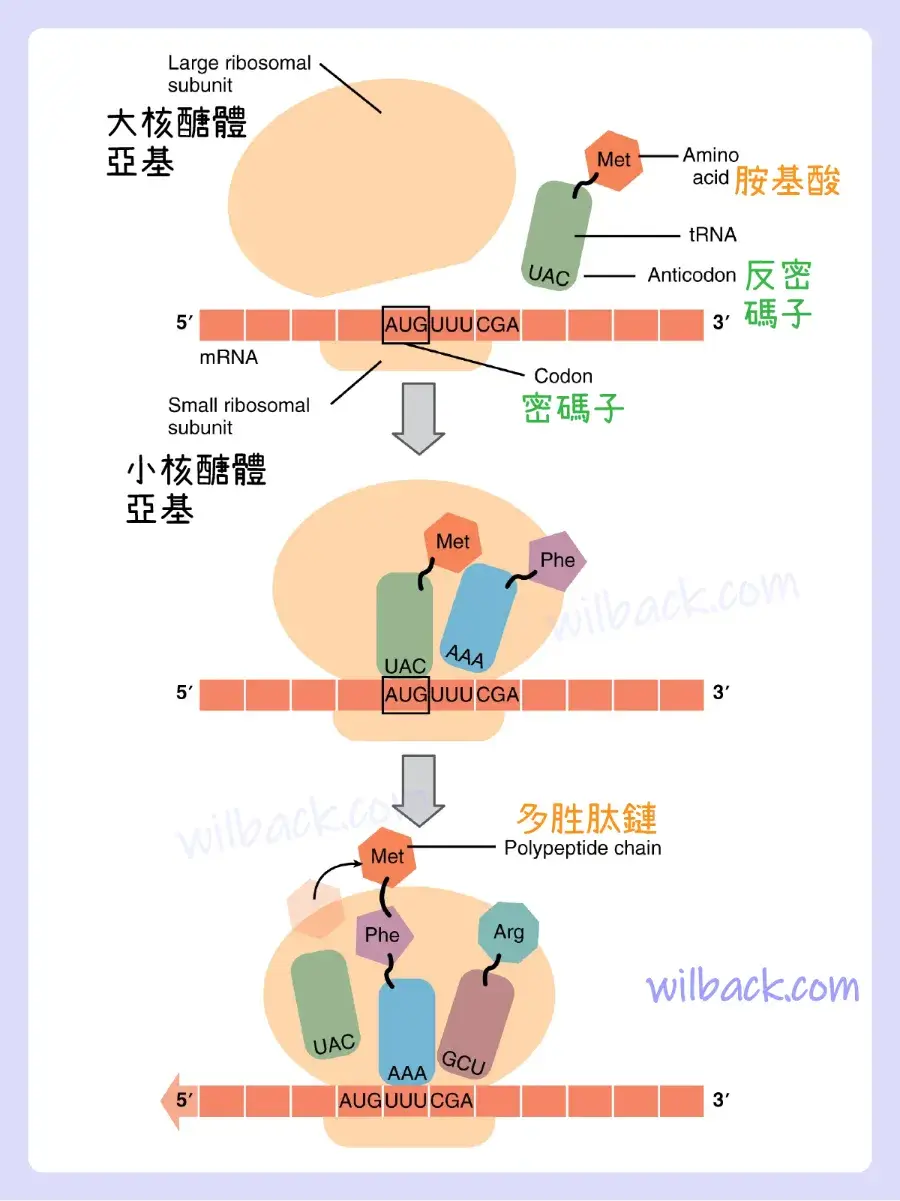
在翻譯過程中,mRNA 轉錄物被由核醣體和 tRNA 分子組成的功能複合物“讀取”。 tRNA 通過將其反密碼子與 mRNA 股上的密碼子進行匹配,將適當的氨基酸按順序添加到不斷增長的多胜肽鏈中。
與 DNA 複製和轉錄過程非常相似,翻譯由三個主要階段組成:起始、伸長和終止。 核醣體與 mRNA 轉錄物的結合開始發生。 伸長階段涉及 tRNA 反密碼子與序列中下一個 mRNA 密碼子的識別。 一旦反密碼子和密碼子序列結合(記住,它們是互補的鹼基對),tRNA 就會呈現其氨基酸貨物,並且生長的多胜肽股〔polypeptide strand〕會附著到下一個氨基酸上。 這種附著是在各種酶的幫助下發生的,並且需要能量。 然後 tRNA 分子釋放 mRNA 股,mRNA 股在核醣體中移動一個密碼子,下一個合適的 tRNA 帶著其匹配的反密碼子到達。 這個過程持續進行,直到到達 mRNA 上的最終密碼子,該密碼子提供了“停止”消息,表明翻譯終止並觸發完整的新合成蛋白質的釋放。 因此,DNA 分子內的基因被轉錄成 mRNA,然後翻譯成蛋白質產物(圖 3.29)。
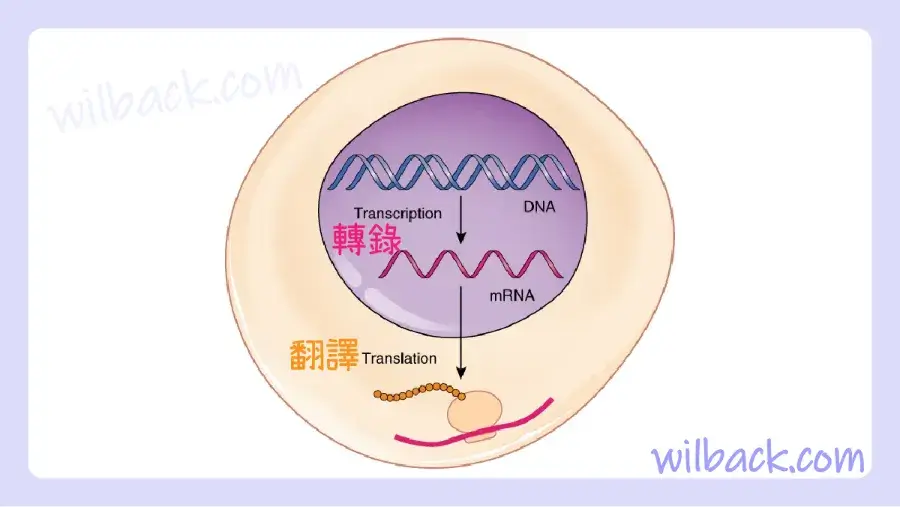
細胞核內的轉錄產生 mRNA 分子,該分子經過修飾後送入細胞質進行翻譯。 在核醣體和 tRNA 分子的幫助下,轉錄物被解碼為蛋白質。
通常,mRNA 轉錄將由幾個相鄰的核醣體同時翻譯。 這提高了蛋白質合成的效率。 單一核醣體可以在大約一分鐘內翻譯一個 mRNA 分子; 因此,單一轉錄物上的多個核醣體可以在同一分鐘內產生數倍數量的相同蛋白質。 多核醣體〔polyribosome〕是翻譯單一 mRNA 股的一串核醣體。
更新紀錄
2023/09/19 發佈本文
評論